打完NOIP后要退役了,闲着无聊写了Zzzyt语言判断器。
第一步:获取数据
从Skype上下载聊天历史数据,并进行处理,可以参考这篇文章HHS Blog。
这是我的源码供参考修改:
1 | import json |
第二步 导入数据到Create ML
将输出文件导入到Create ML中,进行简单训练。 (毕竟我也是ML弟弟,也懒得花时间真正去写tf什么的)
第三步 查看效果
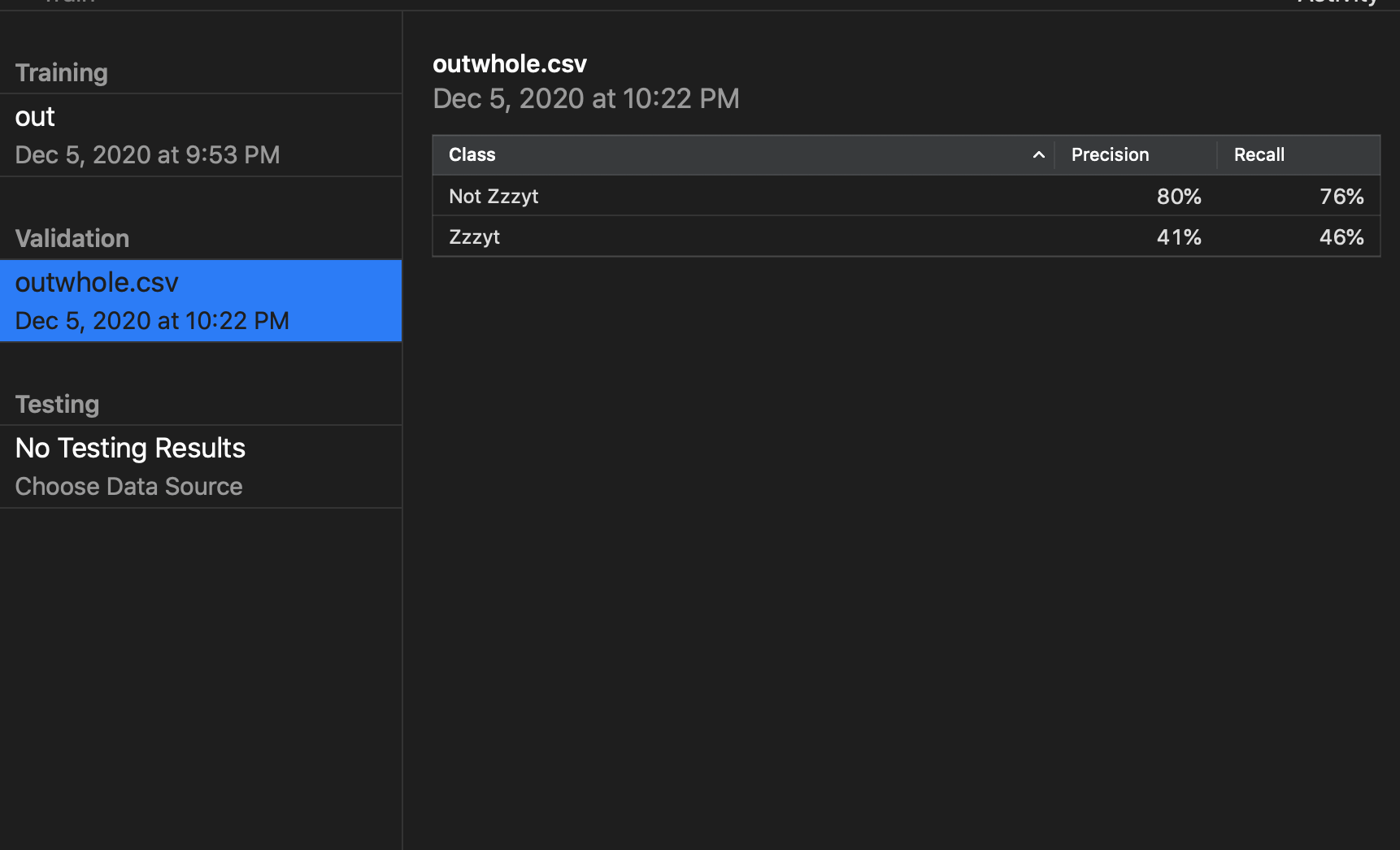
经过简单测试,本模型已经可以简单识别Zzzyt语言习惯,比如im,:?等常用短语表情。
打完NOIP后要退役了,闲着无聊写了Zzzyt语言判断器。
从Skype上下载聊天历史数据,并进行处理,可以参考这篇文章HHS Blog。
这是我的源码供参考修改:
1 | import json |
将输出文件导入到Create ML中,进行简单训练。 (毕竟我也是ML弟弟,也懒得花时间真正去写tf什么的)
经过简单测试,本模型已经可以简单识别Zzzyt语言习惯,比如im,:?等常用短语表情。